The Ingestion Bottleneck: Machine-Centric Performance & Token Efficiency
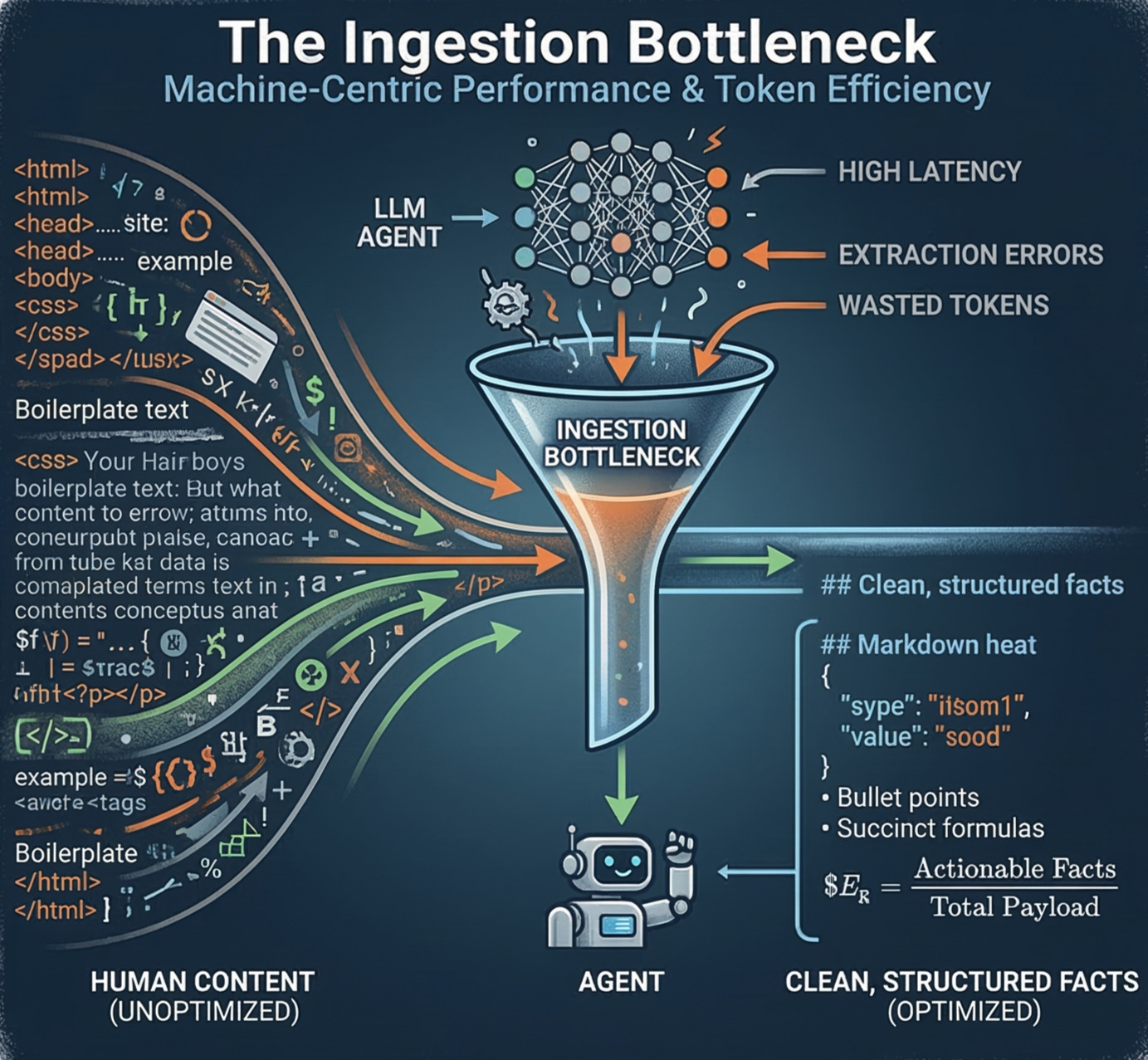
The Ingestion Bottleneck: A Deep Dive into Machine-Centric Performance
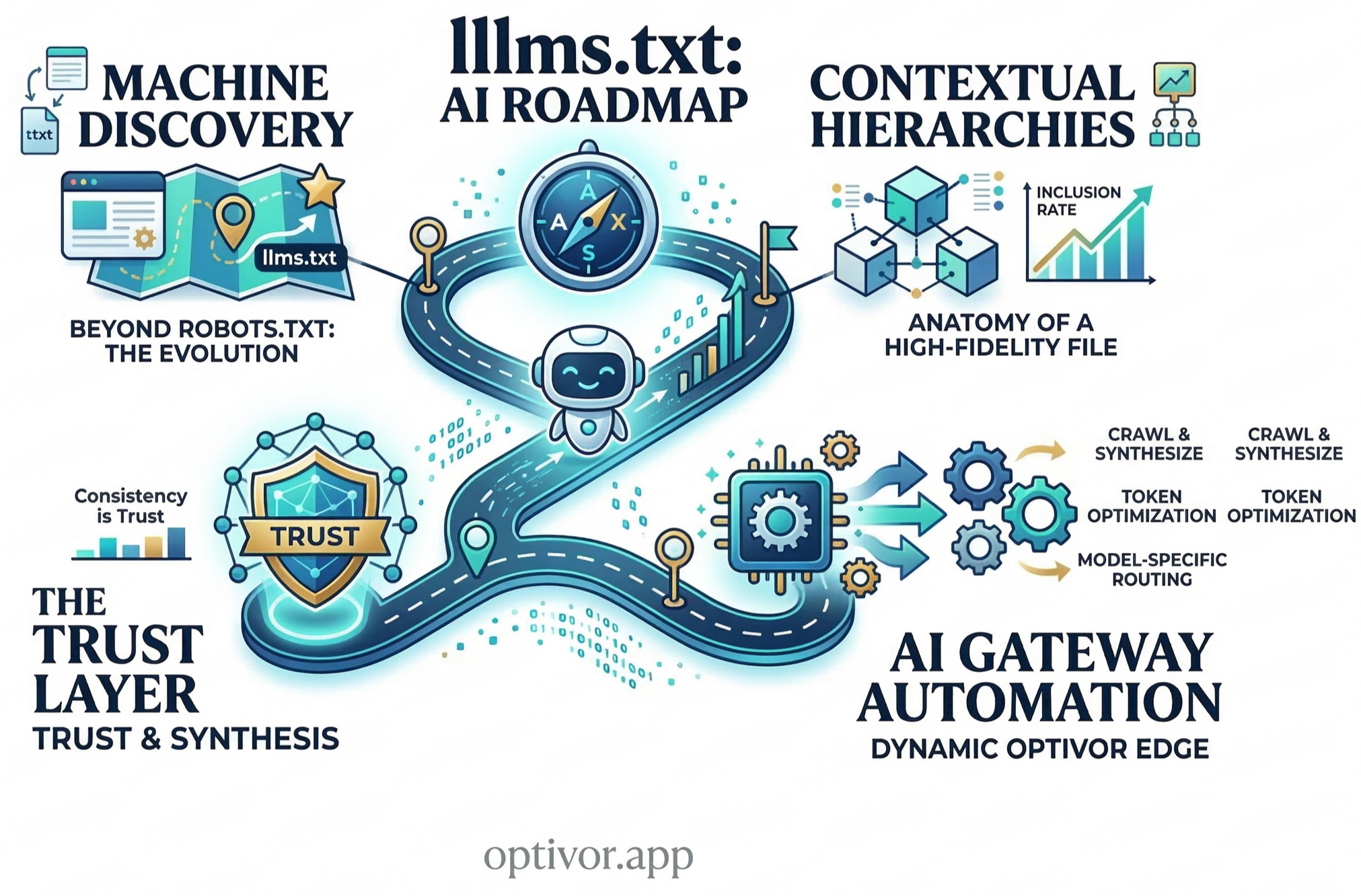
In previous blog, we introduced AXM Agent Experience Management as the discipline of optimizing for agent ingestion, understanding, verification, and citation. This article goes "into the lab" to focus on the most common mechanical failure mode:
A page can be perfectly "fine" for humans, and even indexable by classic search crawlers, but still represent a poor input for an LLM agent.
The Three Pillars of Ingestion Failure:
- Noisy: Excessive boilerplate drowning out core facts.
- Slow: Latency forcing agents to make "budget decisions" (truncation).
- Ambiguous: Weak structure causing extraction errors or hallucinations.
The Core Insight: The ingestion bottleneck is where visibility turns into non-utility.
1. Beyond the Crawler: Reasoning Overhead
Traditional crawlers index text; LLM agents resolve entities, relationships, and intent. When an agent visits your site, it isn't just "reading"—it is performing active reasoning tasks:
- Entity Resolution: Identifying your specific product or brand.
- Intent Mapping: Matching your capabilities to a user’s complex query.
- Constraint Extraction: Pinpointing pricing, security protocols, or integrations.
- Conflict Detection: Checking for internal contradictions.
If your architecture forces an agent to spend extra compute just to recover basic facts, you are effectively taxing the agent’s budget.
| Feature | SEO Strategy | AXM Strategy |
|---|---|---|
| Primary Goal | Indexability (Can the bot see it?) | Extractability (Can the agent use it?) |
| Mental Model | Discovery | Conversion/Citation |
| Success Metric | Search Engine Results Page (SERP) | High-Fidelity Citation |
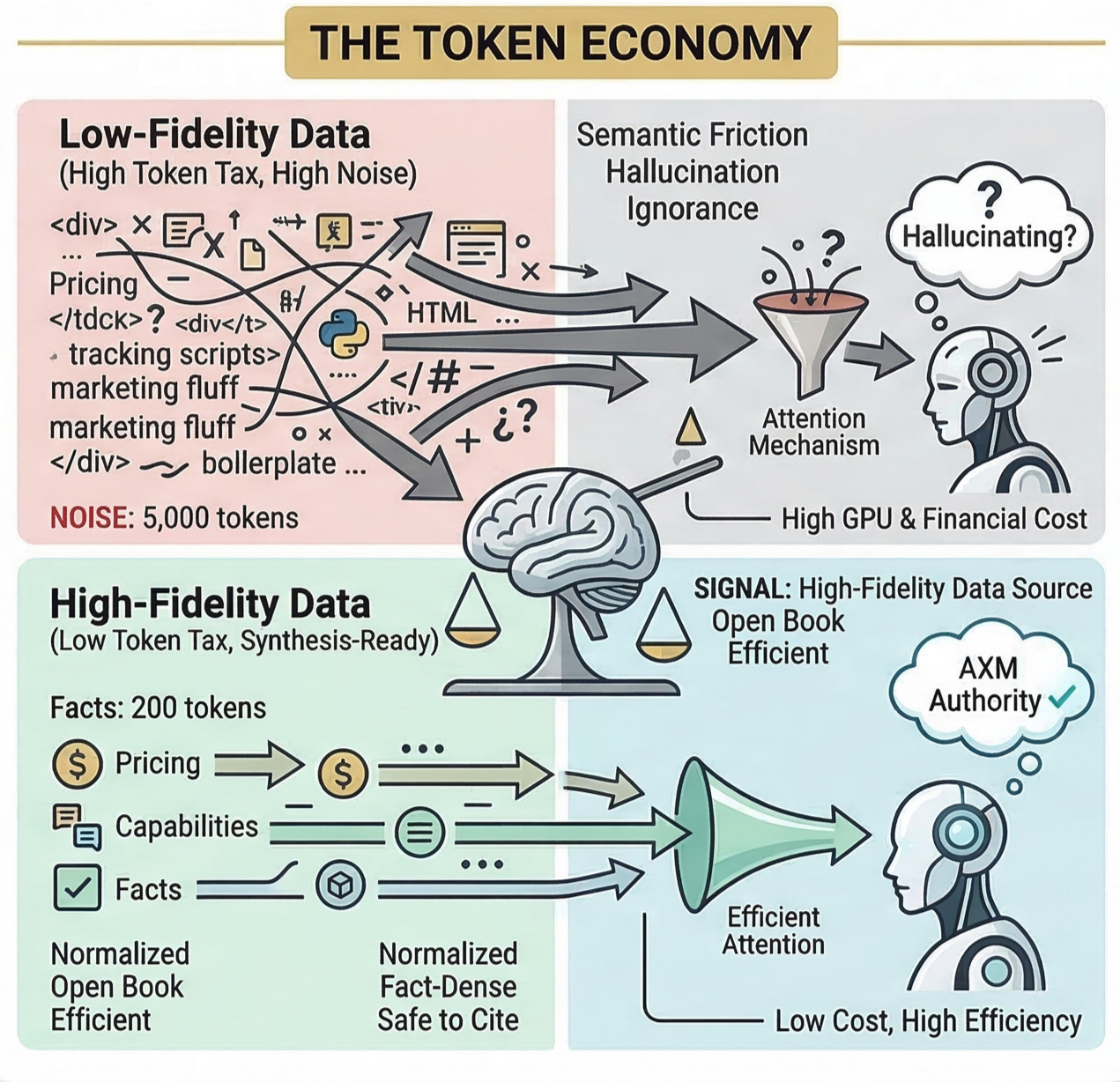
2. The Efficiency Gap (Eg): Quantifying Machine Friction
To optimize for AI, we must quantify the "friction" an agent feels. We use the Efficiency Gap (Eg) formula:
Interpreting the Score:
- High Eg: Lower token cost and higher citation probability. You are providing "useful truth per byte."
- Low Eg: High token cost. Your site becomes a "digital tax" to parse, leading agents to seek alternative, cleaner sources.
What is "Actionable" Content?
Agents prioritize facts they can safely reuse:
- Definitions: Precise "what it is" statements.
- Capabilities: Concrete "what it does" lists.
- Constraints: Pricing, compliance (SOC2, GDPR), and regional availability.
- Interfaces: API documentation and integration logic.
3. Structural Noise: The Silent Killer
Even authoritative sites get skipped if their structure is hostile. Common "Machine Blockers" include:
- Deeply nested
<div>"soup" layouts. - Non-semantic headings (using
<span>with CSS for headers instead of<h1>-<h3>). - Heavy client-side rendering (SPA) that hides content behind JavaScript.
- Redundant navigation menus and footer links that inflate token counts.
AXM Principle: Serve a "Perfect Version"—an agent-facing layer (Markdown or JSON-LD) that preserves meaning while stripping the "visual cruft."
4. Machine Trust & The Semantic Trust Matrix (STM)
Agents don't just parse; they verify. If your marketing site says one thing and your technical docs say another, the agent's confidence score drops. This internal contradiction is called Semantic Friction.
To combat this, we utilize the Semantic Trust Matrix (STM):
- Consistency: Unified naming conventions across all pages.
- Claim Alignment: Matching feature claims between "Hype" (Marketing) and "Reality" (Docs).
- External Validation: Consistent third-party references.
5. Implementation Pattern: The "Perfect Version" Layer
The most effective way to solve the bottleneck is to introduce an agent-native infrastructure layer. This usually involves:
- Optimized Markdown: Exposing a clean version of content specifically for LLMs.
llms.txtImplementation: Providing a standard map for agents to find your most important knowledge.- AI-Native Gateway: Using a CNAME (e.g.,
ai.yourbrand.com) to serve high-density data without altering your main human-facing UI.
Conclusion: Engineer the Answer
Search is evolving into a reasoning engine. If your site behaves like a brochure, agents will treat it like noise. If your site behaves like a high-fidelity data source, agents will treat it like truth.
SEO is the foundation. AXM is the performance layer.